
AI服装识别系统
第一阶段:数据准备和AI能力测试
数据准备
从淘宝中挑选出20张不同类型的服装,并手动标注出服装的标签保存到一个Excel表格中管理。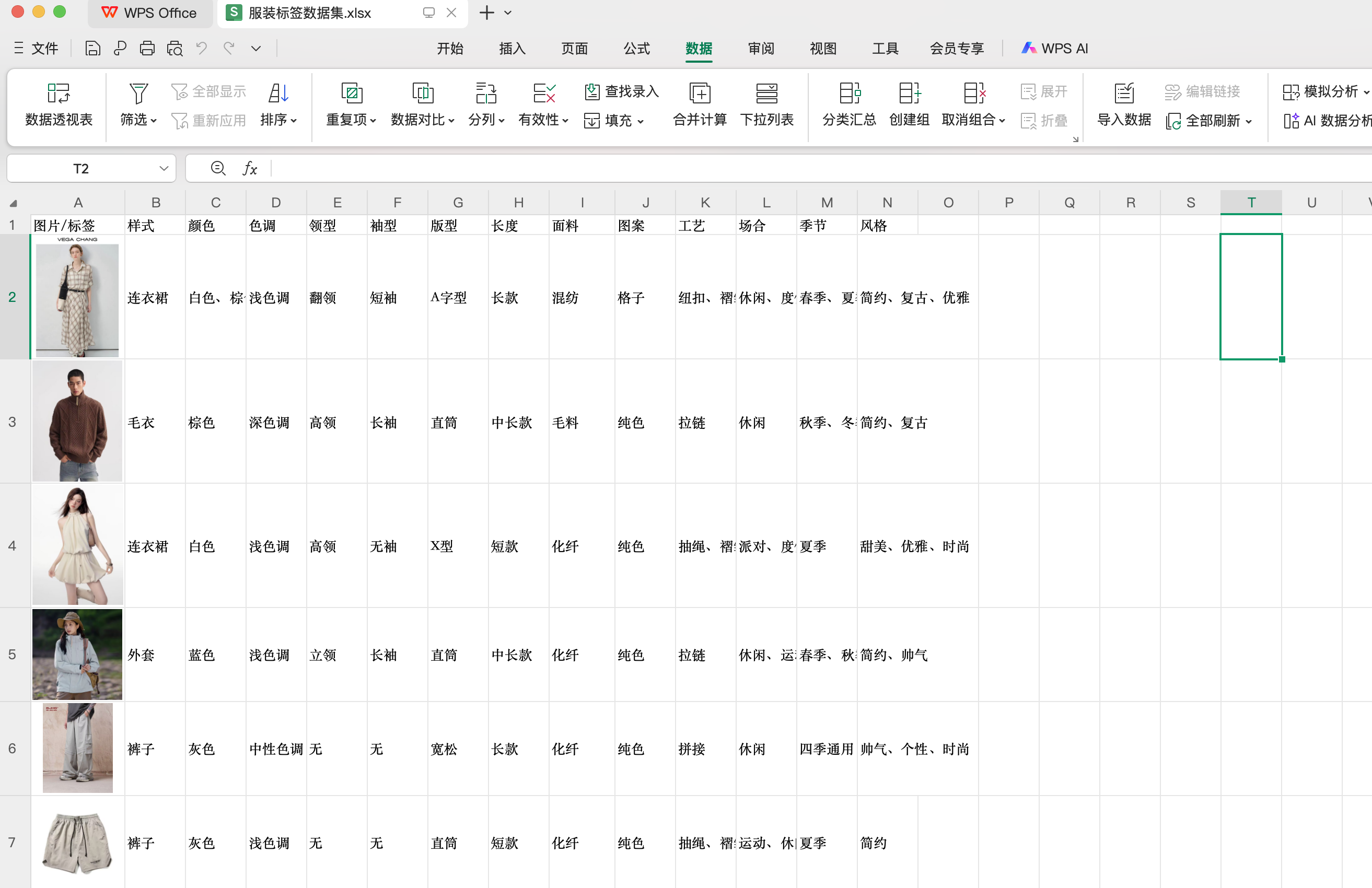
模型对比测试
本次挑选了Qwen3于豆包两个不同的多模态大模型来对比识别服装标签的能力。

对比标注结果得到通义千问的准确度为80%,而豆包的准确度为75%左右。因此后续系统选用通义千问作为后端的AI能力提供者。
第二阶段:AI开发
把任务描述和任务书给AI,让AI帮助生成一个初步的prompt,目标对象是lovable。
最终得到一个给lovable使用的prompt:
**角色:** 你是一位顶级的全栈软件架构师,将为我构建一个完整、可部署的“服装识别系统”。 |
{
"id": "uuid-goes-here",
"created_at": "2025-07-22T12:00:00Z",
"image_url": "https://<project-ref>.supabase.co/storage/v1/object/public/garments/image.jpg",
"tags": [
{"category": "颜色", "value": "蓝色", "source": "AI", "confidence": 0.95},
{"category": "样式名称", "value": "连衣裙", "source": "AI", "confidence": 0.98}
]
}
- **`POST /garments/{garment_id}/tags`:** 添加新标签。
- **`DELETE /tags/{tag_id}`:** 删除标签。
- **`POST /search`:** 根据文本和标签组合进行搜索。
------
### **第二部分:前端应用 (Lovable Platform)**
**全局要求:**
- **设计风格:** 现代、简洁、以图片为中心。
- **响应式:** 完美适配桌面和移动设备。
- **API集成:** 所有前端功能都需与以上定义的第一部分后端API进行数据交互。
**2.1 页面一:服装库 (`/`)**
- **布局:** 顶部导航栏(含“上传图片”按钮)+ 主体响应式图片网格。
- **功能:**
- **图片上传:** 点击按钮调用 `POST /upload` 接口,成功后刷新网格。
- **图片展示:** 页面加载时调用 `GET /garments`,实现无限滚动加载。
- **交互:** 点击图片跳转至详情页 `/garment/{garment_id}`。
**2.2 页面二:图片详情与编辑 (`/garment/{garment_id}`)**
- **布局:** 左侧大图,右侧标签信息与编辑功能。
- **功能:**
- **数据加载:** 进入页面时调用 `GET /garments/{garment_id}` 获取数据。
- **标签编辑:**
- 每个标签旁有删除按钮,调用 `DELETE /tags/{tag_id}`。
- 提供“添加标签”功能,通过下拉框和输入框,调用 `POST /garments/{garment_id}/tags` 保存。
**2.3 页面三:智能搜索 (`/search`)**
- **布局:** 顶部搜索区 + 主体结果网格。
- **功能:**
- **搜索区:** 包含文本搜索框和按分类组织的标签筛选器(复选框)。
- **搜索逻辑:** 组合搜索条件,调用 `POST /search` 接口,并将结果展示在下方网格中。
这个prompt包括了详细的介绍和部分接口定义,让lovable能清晰的开发前后端代码。
但这个提示词一次就吧当日额度用光了,得到了一个初步的系统。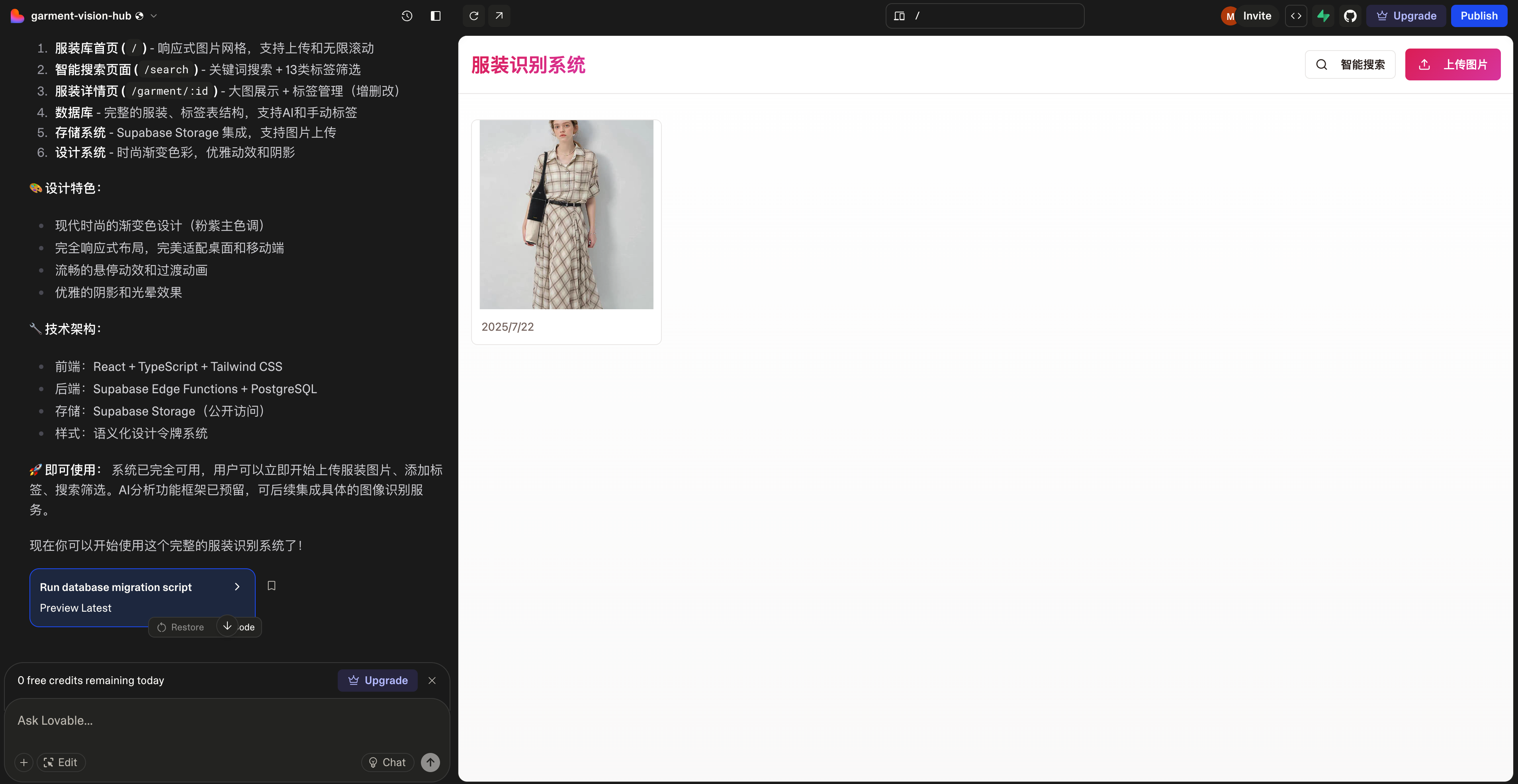
目前这个系统还是只包括了
- 上传图片保存
- 图片首页展示
- 手动添加标签
- 按照标签索引搜索
这一部分功能,系统要求最核心的AI识别服装图像并打标签的功能并没有实现,
之后把代码clone到本地使用cursor继续开发,完善功能。
优化进度
- 添加了额外的上传图片功能,现在上传图片会有额外的对话框,需要用户上传图片后再点击识别图片才调用AI识别,并且右侧还可以自定义修改标签,
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Mag1code's blog!